
Background

Toontown Rewritten is a completely free to play, volunteer maintained Massively Multiplayer Online Role-Playing Game (MMORPG) built on top of Disney's Toontown Online, discontinued in 2013.
In the process of revitalizing the discontinued Toontown Online, several pieces of infrastructure to get the game up and running needed to be rebuilt. Because the project is volunteer run and did not accept money from players, the infrastructure in place to keep the game running, maintain support, and distribute patches was under a very tight budget constraint.
As of this writing, Toontown runs in a Kubernetes instance across a few virtual machines provided for this purpose on a minor cloud provider.
The deployment infrastructure, largely designed due to necessity at the project's inception, was a source of technical debt. A deployment could only be done by a subset of the small programming team, as an internal runbook developed out of habit (undocumented), and involved setting up a local Kubernetes deployment environment and access tokens before invoking a series of commands manually.
In 2020, due to factors beyond our control (not as a result of technical debt), this deployment mechanism was rendered unusable and we were forced to address the issue from scratch.
Problems to solve
- We were unable to deploy client and server updates to the game. (However, because we had only lost control of the deployment infrastructure, the game availability was not at risk.)
- We wanted to design a deployment system which was automated as much as possible.
- We wanted the deployment system to be able to be invoked by any technical member of the team (i.e., any programmer, QA, devops staff, leads, etc.)
- We needed to develop and test this system under the existing constraints of our machines, without compromising production traffic.
Solution
An artifact of the broken existing deployment system was a deployment.json file, used to specify all Kubernetes resources related to the deployment. We decided to split the artifact into several pieces and package them all together into a Helm chart.
Helm charts are versioned collections of declared Kubernetes resources, with templated configuration filled in at deployment or upgrade time. Since we maintained three game environments (dev, QA, and prod), this allowed us to design our package in a generic fashion, and enable/disable/configure features or variables as required.
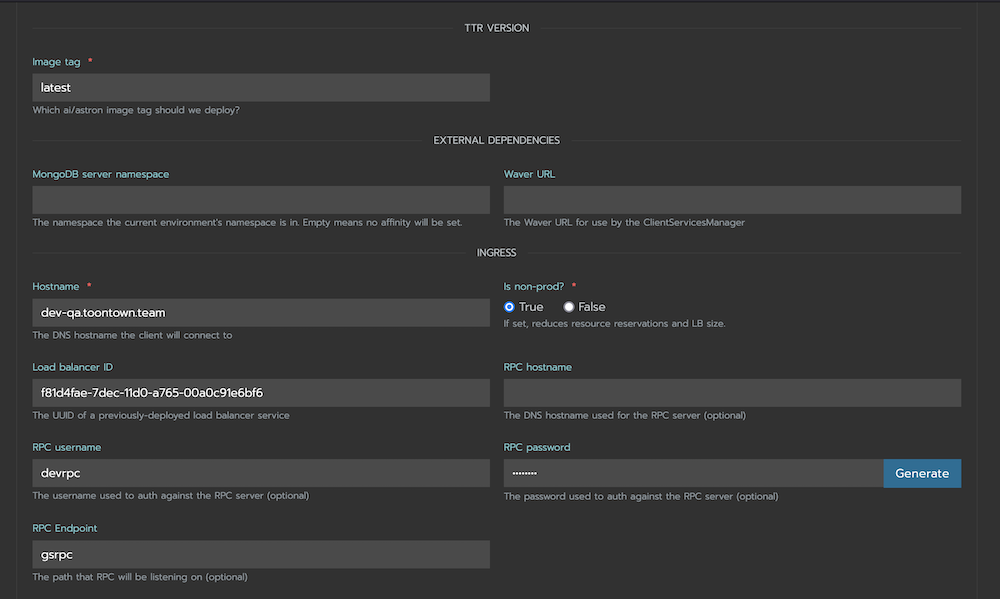
We wrote a CI deployment flow to automatically assemble, package, and deploy this Helm chart to a Helm repository hosted within the Kubernetes cluster. This repository was specified via a Dockerfile to produce an image, which was then deployed.
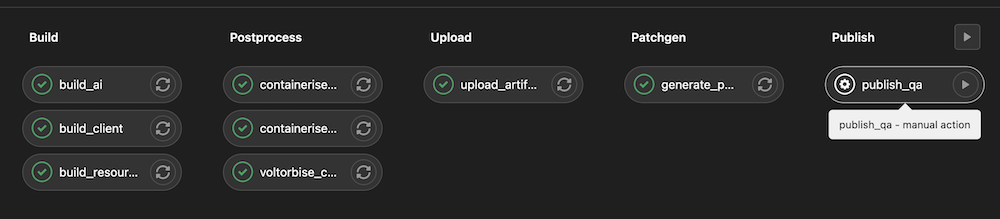
The automation to deploy an update across an environment, or distribute a client update, was written but kept deliberately manual (as an untimely release of either had the potential to cause availability issues). When ready, this automation could be triggered by clicking a button.
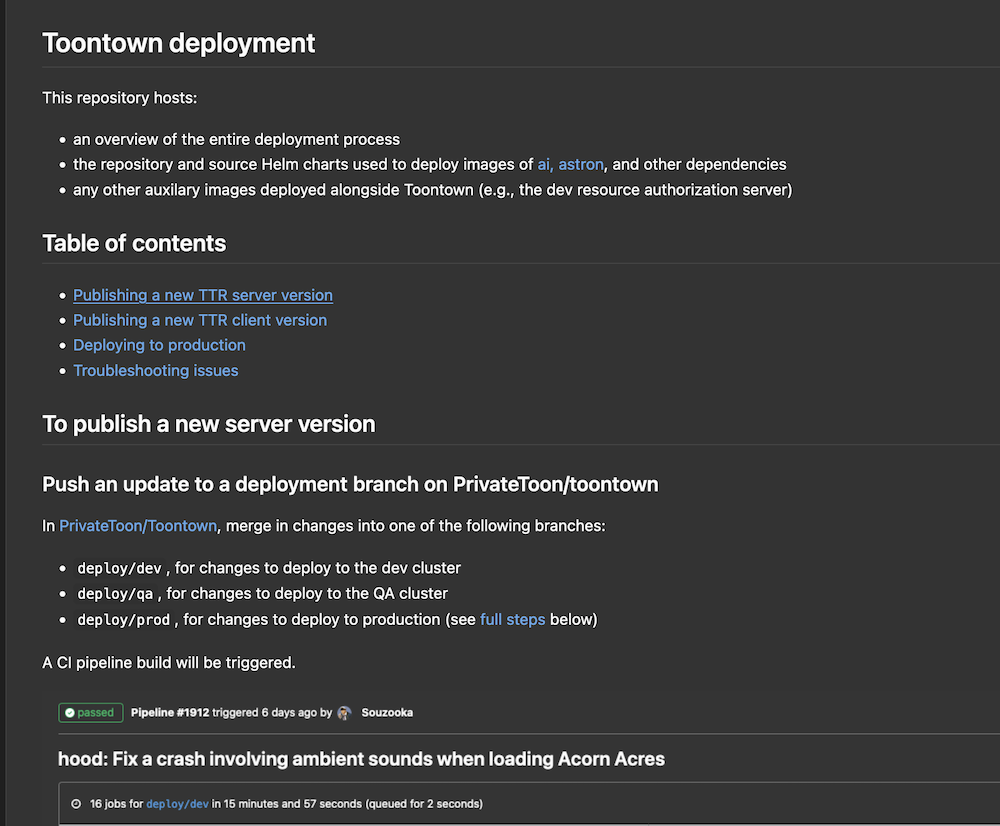
Finally, everything to expect during a deployment, including the precautions to take before deploying to production, was documented in a readme file within the deployment repository.
Result
Other than recovering the ability to publish deployments, the team had the bonus effect of no longer needing to wait for dedicated availability of the devops members of the team to deploy an update. Once an update was approved, anyone would be able to deploy it. This increased update velocity against the dev and QA environments, allowing changes to be tested faster where possible without devops involvement.