
Background
Managing MySQL database hosts was previously done via a series of scripts invoked inside a special script directory on the hosts themselves. Some examples of these scripts were:
- Bootstrap a host: Prepare an empty Linux machine into a MySQL database host, integrated with our existing infrastructure, and ready to have user databases deployed to it.
- Build a replica: Prepare an empty Linux machine into a replica MySQL database host against a provided existing primary database host.
- Move CNAME: Move the DNS record associated with a primary or replica MySQL host from one host to another.
However, since their creation, management and running of these scripts began to prove move and more problematic over time:
- The scripts did not display progress, leading to confusion as to whether they were running or hung.
- The scripts hung or crashed often, due to a combination of script, metadata, or networking issues.
- When the scripts crashed, they didn't provide any reason (stack trace or otherwise) as to the reason for their failure, making issues close to impossible to identify.
- The scripts pulled down configuration and software packages from "special hosts" which also hosted databases -- if these databases were ever failed over to a replica, the scripts to prepare new hosts would fail.
- The network security policy, designed with users in mind, changed significantly since initial development of the scripts. As a result, scripts would often get stuck on user input, wait for a password/2-factor token which would never arrive, or time out due to the firewall. Some workarounds were added to the scripts, which did not consistently work.
The ultimate solution was to migrate to a host management platform built on top of Puppet, which was in development by another team at the time. However, to buy our team time, something needed to be done as an intermediary solution without too much change/retraining into how the team was accustomed to preparing and managing hosts.
Assertions
All operations on a host were broken down into individual runbooks, with the following design goals in mind:
- Runbooks should be atomic; they should completely succeed or be completely rolled back.
- Runbooks should be able to be run from a consistent location.
- Runbooks should be written in a clear pattern, as a series of steps from top to bottom, making it easy for a human to read and parse what it does.
- Runbooks should never get stuck; intermediary steps should always be associated with an active process or function call or fail gracefully. A state which is waiting on user input should be forwarded to the user who started the runbook or fail immediately if user input is not possible.
- Runbooks should plan for failure; a failure in an intermediary step should explain to the user exactly what has failed, the stack trace (if available), and manual resolution steps to complete the runbook manually from the point at which it has failed.
- Runbooks should fail as early as possible; they should prompt for parameters, decide, and verify as much as possible prior to executing anything, as not doing anything is cheaper than failing halfway and rolling back.
Design
Development of mysqltool began by reverse-engineering existing scripts into a series of exact manual steps that a human could run. This was a time-consuming process, as these scripts tended to be a bit messy and a bit over-optimized; sacrificing code clarity for the sake of minor performance optimizations.
Next, for each script, each step which relied on a prior decision to be made was flagged.
If the host is to run MySQL version 8.x, run...
If the host exists in the staging environment, change...
At this point, prompt the user for their password...
Populating all of these variables was merged into a single step called step 0, which would be run prior to the others. In addition, combinations of variables which would lead to undefined behavior later on were identified as situations where the new script would fail early.
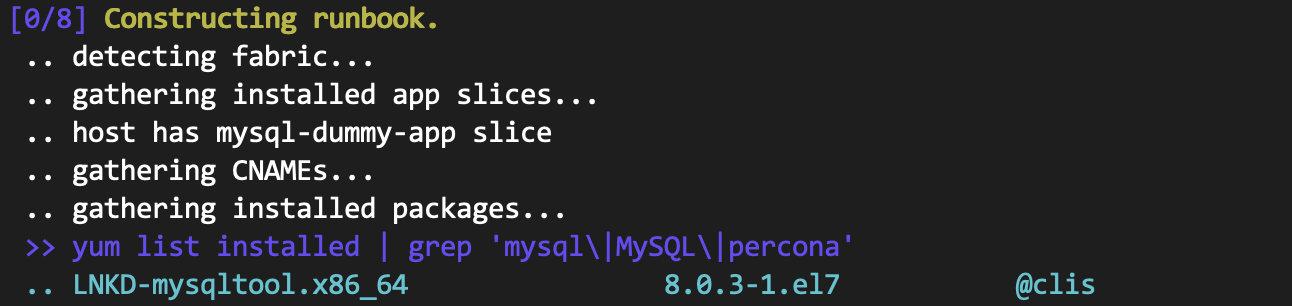
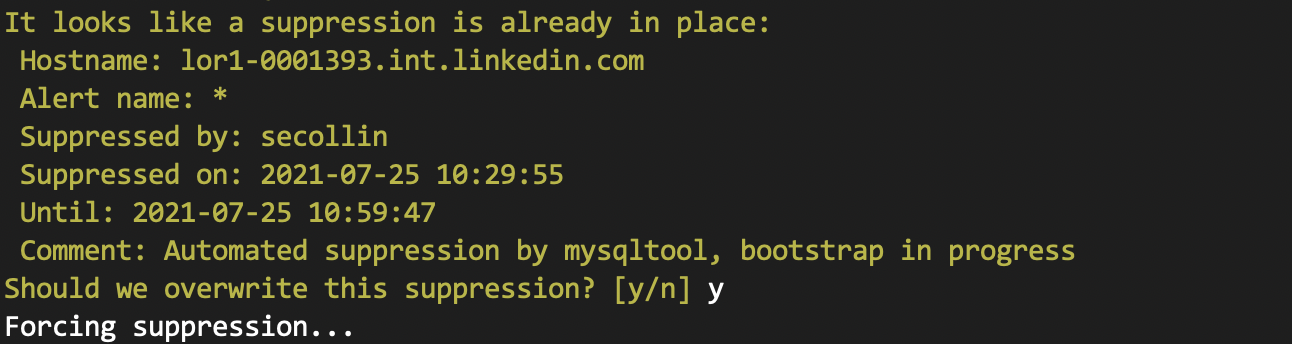
The exact manual steps were committed into code to start the runbook. Steps which required a decision were exposed as templates, which would be fully rendered after completion of step 0. Configuration files were translated from existing individual files (on the "special hosts" mentioned above) tailored for several different configurations to single, templated files in code. That way, in the event of failure, the user would be presented with a completed manual runbook from the point of failure and would not have to make any decisions themselves.
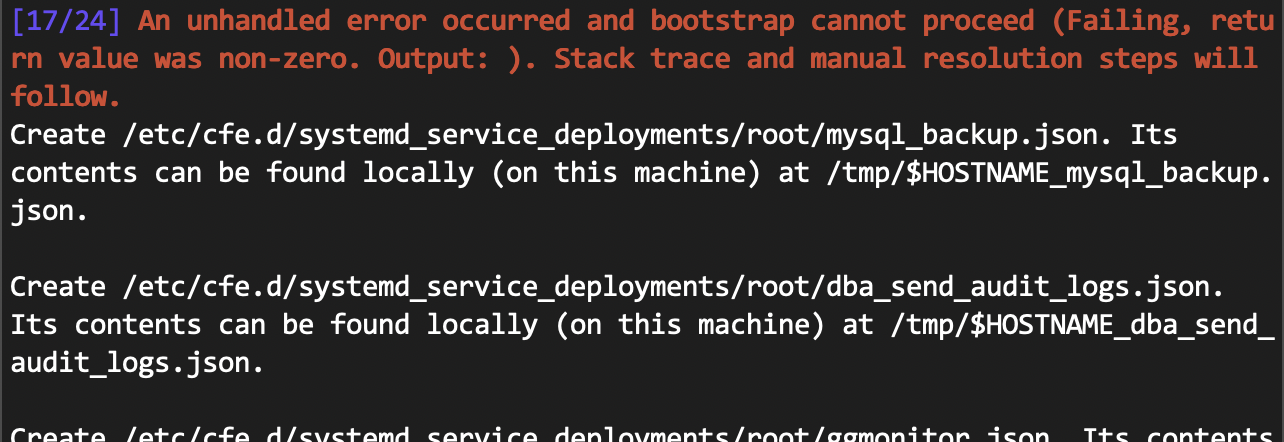
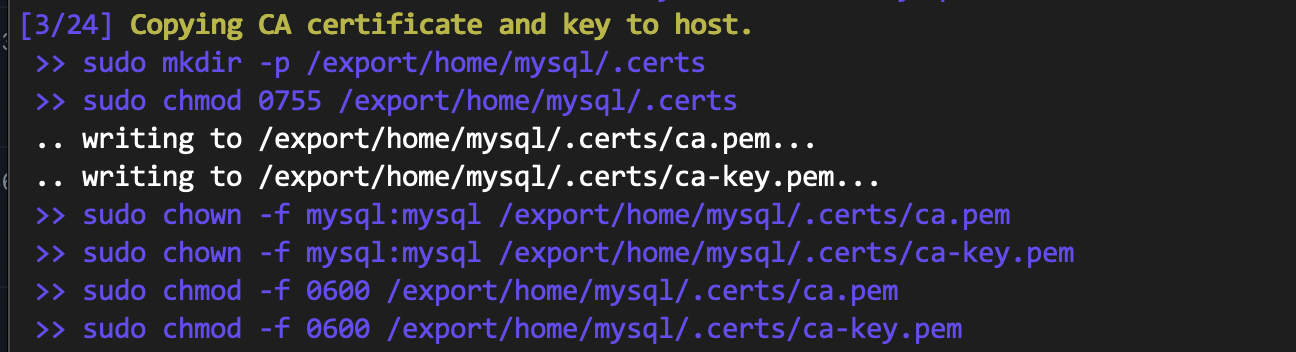
Each manual step was translated into an automated step in code. Each automated step, when run, would show:
- The numbered step in the runbook
- The number of steps remaining
- A human-readable summary of what the runbook was doing in that step
- Exact shell commands executed within that step (if any)
- Stdout/stderr returned as a result (if any)
Finally, all runbooks were wrapped into a single executable and automatically distributed to the machines of all members of the team. They could now be invoked from the user's dev machine instead of having to connect remotely to the machine to be prepared.
Result
Host management overhead reduced significantly after mysqltool was made available, with the old scripts quickly falling into disuse. Time spent preparing a host reduced from an average of 40 minutes, including time for active troubleshooting, to about 15 minutes of largely "fire-and-forget" invocation. The number of hosts with inconsistent configuration or in a half-completed state dropped to nearly 0 a few months after the tool was released, and remained consistent ever since. The runbook model of structuring the automation was easy to understand, allowed new engineers to quickly submit bugfixes soon after their onboarding, and was reused to build further automation by other members of the team.